ActifDémarré octobre 2025· Mis à jour juin 2026
zaki-ns CMS Architecture Lab
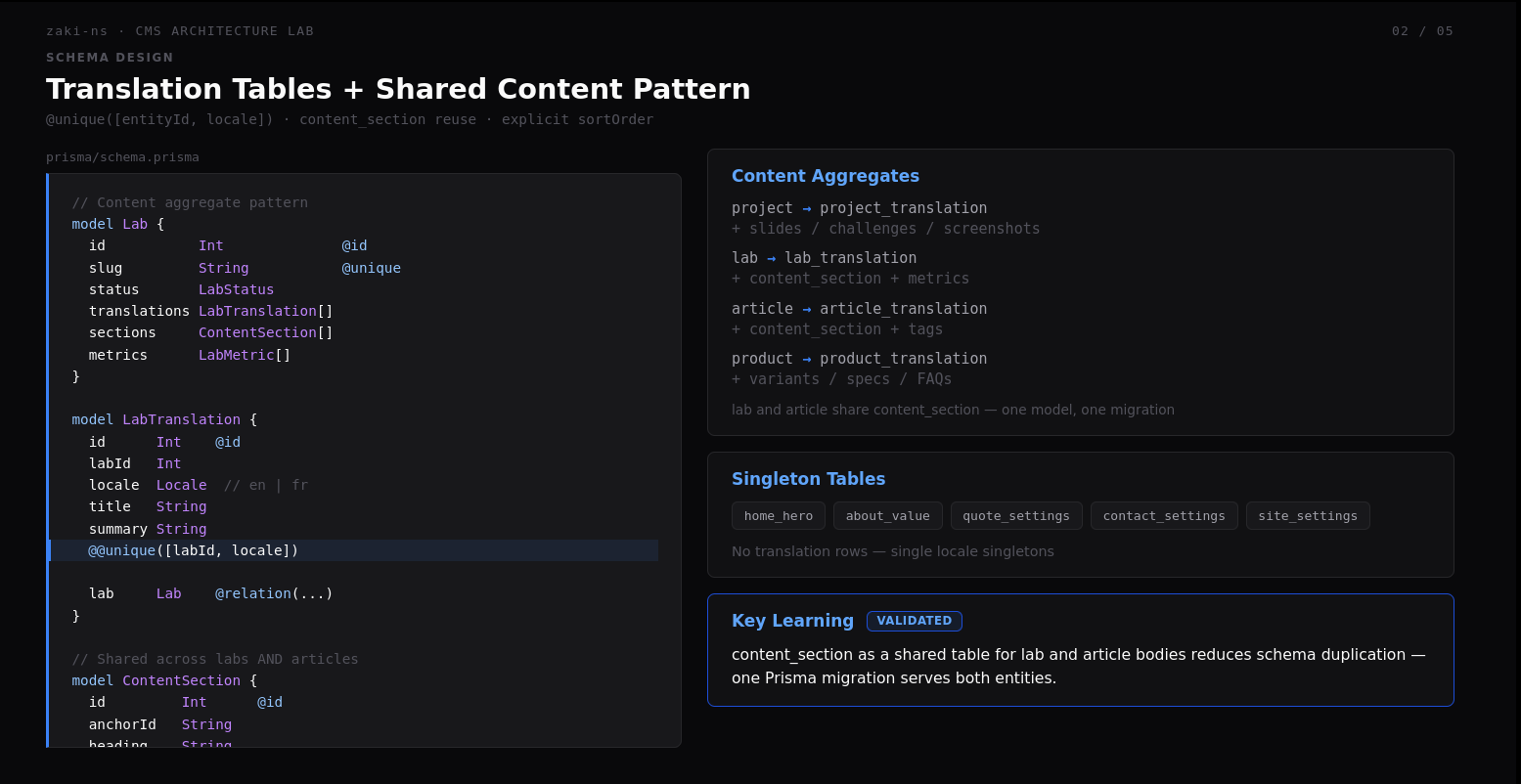
This lab documents the architecture decisions behind the zaki-ns Platform—Prisma schema design, JSON seed pipelines, withDbFallback getters, and revalidateTag patterns that keep admin edits visible on the public site without redeploying.
Signaux d'expérience
- Prisma models
- 50+
- Content aggregates
- 10
- Public locales
- 2
Next.jsPrismaPostgreSQLTypeScriptnext-intlDocker